Blog News
Automatisiertes Maschinenlernen im Kontext von SPA
MLOps, das sind die besten Praktiken und Werkzeuge, um das Ende-zu-Ende Maschinenlernen zu erleichtern.
Obwohl MLOps immer beliebter wird, fehlen jedoch noch wichtige Funktionen, um ein erfolgreiches Beispiel für einen ML-Prozess in eine wiederholbare und automatisierte ML-Trainingspipeline zu überführen.
In industriellen Anwendungen, aber auch im automatisierten Training von Surrogatmodellen im SPA Kontext, ist ein automatisiertes ML-Training erforderlich. Jedes Datenset repräsentiert dabei unterschiedliche Konzepte, was zur Entwicklung zahlreicher unterschiedlicher Vorhersagemodelle führt. Jedes neue Modell erfordert eine einzelne Validierung durch Fachexperten.
Hier kommt die Integration von Vorwissen bei der Modellbildung ins Spiel. Diese Integration hilft, die Eigenschaft von Vorhersage-Modellen vorzugeben und dadurch den Bedarf an menschlicher Interaktion bei der Modellvalidierung zu reduzieren.
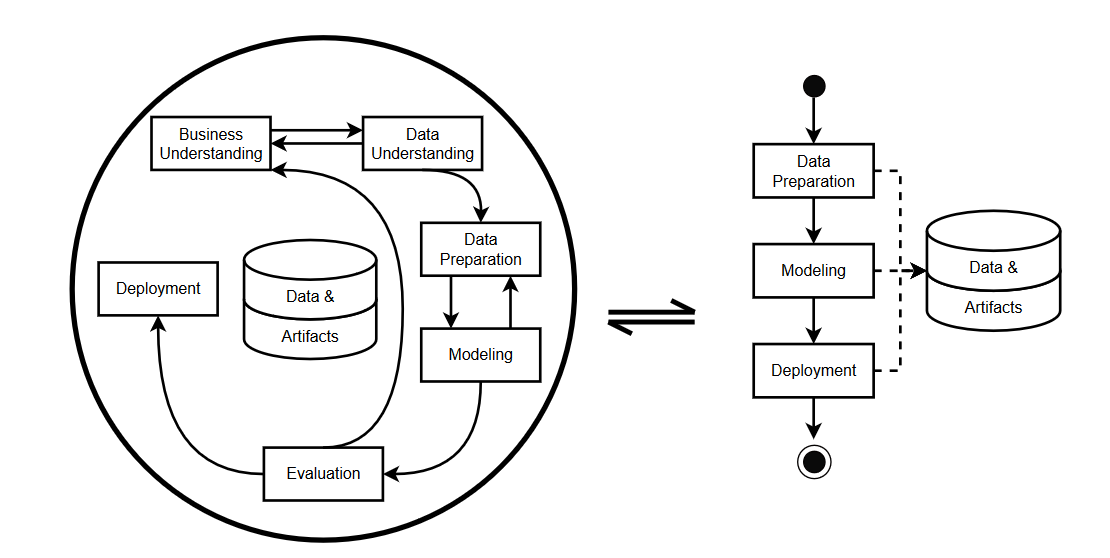
Um eine vollständige Automatisierung des ML-Trainings zu erreichen, wird eine Unterscheidung zwischen zwei Phasen vorgeschlagen: Die explorative Phase beinhaltet die datenwissenschaftlichen Aufgaben, welche nach dem CRISP-DM-Modell verlaufen. Die exploitative Phase implementiert die ML-Pipelines basierend auf den etablierten Arbeitsabläufen und führt sie für neue Daten durch (vgl. Bild).
Die Nutzung von ML-Algorithmen und Methoden, die das Wissen von Fachexperten integrieren können, ist ein wichtiger Aspekt, um den Übergang von Phase eins zu Phase zwei zu erleichtern. Mit dieser Methode können Vorhersagemodelle erstellt werden, die keine manuelle Validierung mehr benötigen.